DataWeave 2.2 - Additions to the Arrays Module, Part 2
Learn how to use the join functions added to the DataWeave Arrays module in Mule 4.2.

Introduction
This post will examine the remaining additions to the DataWeave Arrays module that weren’t covered in Part 1, the join functions. In the 4.2.0 Mule Runtime, DataWeave now has three new additions to the Arrays module that give us SQL-esque joining functionality. These functions and their corresponding doc pages are:
join- documentation,leftJoin- documentation,outerJoin- documentation
In the first section I'll introduce the concept of joins. Feel free to skip that section if you're already familiar with joins (from SQL, for example). In the second section, I'll discuss how the join functions go about determining if a relationship exists between items in two sequences of data. Lastly, we'll cover the specifics of join, leftJoin, and outerJoin, as well as some potential use cases for these functions.
I'm going to leave out the DW header in the code examples for the sake of brevity. Know that if you want to try this yourself, you'll need to import the Arrays module:
import * from dw::core::Arrays
What is a join?
Joins are all about relationships between items in two sequences of data. They are a means of collecting two separate but related pieces of data into a single unit. You're joining two related data sets into a single data set. If you've worked with relational databases like PostgreSQL before, you may have seen joins in your SQL code when querying two related tables:
select customers.name invoices.amount, invoices.due_date
from invoices
join customers on invoice.customer_id = customers.id;
That query is joining data from the invoices table and the customers table into a single result set that contains data from both. Imagine we have an invoices table that looks like this:
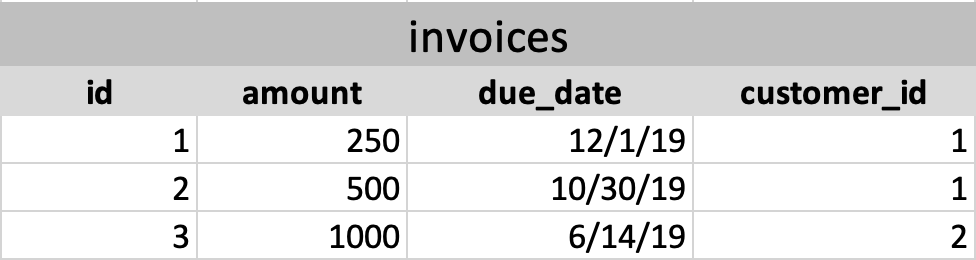
and a customers table that looks like this:
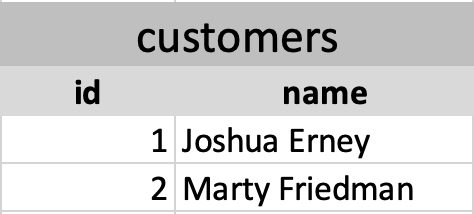
After the SQL executes, it will return this:
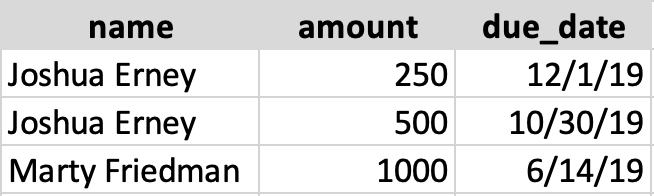
As you can see, the result set is a combination of the two tables. Each row is an instance where invoice.customer_id was equal to customers.id. That's essentially all joins do.
The join Functions: Finding IDs
The join functions in DataWeave share the same spirit as SQL joins but the input and output are different. As input, the join functions take two Arrays (much like how SQL joins take two tables). In SQL, we deal with 2-dimensional data. SQL tables only have rows and columns. In DataWeave, however, we can have as many dimensions as the language allows. Our rows and columns can additionally have more rows and columns. Imagine a heavily nested XML element, for example. Because of the potential for handling data that is n-dimensional, DataWeave must supply a more flexible way of specifying an ID. Like anywhere else in DataWeave where we need a ton of flexibility in how we do something, functions will be the tool for the job.
In addition to the two input Arrays, the join functions take in two functions that are meant to identify where to find the ID of an item in each Array. First, let's break down what that means. We can cover this once and understand the basis of how all the join functions work because all the join functions are higher-order functions that take in functions to define the IDs.
Let's assume we have an Array like below:
[
{
"id": "1",
"name": "Joshua Erney"
},
{
"id": "2",
"name": "Marty Friedman"
}
]
How might we go about defining how to find the unique identifier for each item in the Array, knowing that the unique identifier is the "id" field? We would use the following lambda to specify how to find the ID:
(obj) -> obj.id
When I say this function defines how to find the unique identifier for each item in the Array, I just mean that if you feed each item in the Array to the function, you should get back the ID. You should be able to pass that same function to map and get back a list of IDs for your input Array (highly recommended for debugging):
var arr = [{"id": "1", "name": "Joshua Erney"}, ... ] // Same as above
var ids = arr map (obj) -> obj.id
---
ids
// Returns ["1", "2"]
In our example above, we have a 2-dimensional data structure, just like a SQL table. Each key in an Object is like a table column name, and each Object in the Array is like a table row. This will not always be the case. Take this data for example:
[
{
"name": "Joshua Erney",
"meta": {
"id: "1",
"creationDate": "2019-01-01T00:00:01.594"
}
},
{
"name": "Ronald Dennis",
"meta": {
"id: "2",
"creationDate": "2019-06-01T12:34:34.700"
}
}
{
"name": "Marty Friedman",
"meta": {
"id: "3",
"creationDate": "2019-01-05T23:00:04.668"
}
}
]
Here we have more than 2 dimensions. We still have keys for the Objects that can be thought of as column names, as we have an Array of Objects where each Object can be thought of as a row. However, those Objects also contain another Object, adding a dimension to the data. To get to the ID in this case, we need to dig in an additional level.
(obj) -> obj.meta.id
Keep in mind that we can easily support composite IDs as well. Composite IDs are IDs that are created from two pieces of data instead of just one. Perhaps we need a combination of "id" and "creationDate" to create a unique ID. We could do this:
(obj) -> obj.meta.id ++ obj.meta.creationDate
Now that we understand how the functions passed to the Join functions are used, we can begin to explore how join, leftJoin, and outerJoin work and when we might use them.
join
join is a useful function for when you have two Arrays that contain some related data, you want to pair off all of the related data, and ignore the rest (i.e., that data will not make it into the output). I find that this concept is much easier to visualize than to read:
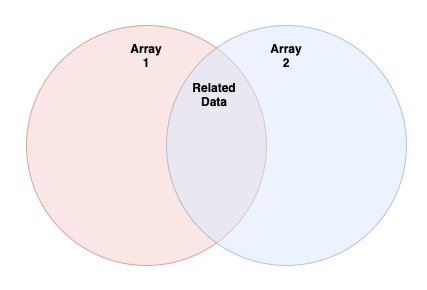
In the Venn diagram above "Array 1" is all the data in the first Array passed to join, "Array 2" is all the data in the second Array passed to join, and "Related Data" are the data items from "Array 1" and "Array 2" that are related to each other by a definition of your choosing.
Using the diagram above as a reference, we should use join when we're interested in finding the "Related Data" between "Array 1" and "Array 2". If "Array 1" contains users and "Array 2" contains orders, "Related Data" would be a list of users with their related orders. Remember, joins are all about relationships. join only cares about the data where it can verify a relationship exists between two pieces of data. join will ignore any data for which it cannot verify a relationship.
To continue our hypothetical example, let's say we have two Arrays, one called users and the other called orders:
var users = [
{
"id": "1",
"name": "Jerney"
},
{
"id": "2",
"name": "Marty"
},
{
"id": "3",
"name": "Daren"
}
]
var orders = [
{
"id": "12",
"user_id": "1",
"product": "ham"
},
{
"id": "13",
"user_id": "1",
"product": "broccoli"
},
{
"id": "14",
"user_id": "2",
"product": "guitar strings"
},
{
"id": "15",
"user_id": "999",
"product": "book"
}
]
Let's talk about this data for a little bit so we know what we're getting into. Users contains three users, Josh, Marty, and Daren. Orders contains four orders, one for ham, one for broccoli, one for guitar strings, and another for a book. Both Arrays contains Objects that can be identified by their "id" field. Orders also has a "user_id" field that is like a foreign key, relating an order back to a user. If we look closely, we'll see that a "user_id" of "3" never appears in the orders; Daren has no orders. Also notice that the users Array does not contain a user associated with the last order in the orders Array.
Given what we discussed in the previous section, we know that we need to use a function for each Array to identify the ID for each item contained in the Array. Let's write those now so we can finish defining the input for join:
// To get the id of each user:
(user) -> user.id
// To get the id of each user in an order:
(order) -> order.user_id
Now we have all we need to check out our join function. Let's give it a go:
join(users, orders, (user) -> user.id, (order) -> order.user_id)
// Returns:
// [
// {
// "l": {
// "id": "1",
// "name": "Josh"
// },
// "r": {
// "id": "12",
// "user_id: "1",
// "product: "ham"
// }
// },
// {
// "l": {
// "id": "1",
// "name": "Josh"
// },
// "r": {
// "id": "13",
// "user_id: "1",
// "product: "broccoli"
// }
// },
// {
// "l": {
// "id": "2",
// "name": "Marty"
// },
// "r": {
// "id": "14",
// "user_id: "2",
// "product: "guitar strings"
// }
// }
// ]
A Note About the Output of the Join Functions
It's important to note that join, leftJoin and outerJoin output the same type of data. Let's look at the first Object that was returned in the previous example:
{
"l": {
"id": "1",
"name": "Josh"
},
"r": {
"id": "12",
"user_id: "1",
"product: "ham"
}
}
The Object contains two keys, "l" and "r", which we can safely assume stand for "left" and "right". In DataWeave, this type of Object is referred to as a Pair. Notice that the "l" key contains an item in the first Array we passed to join, while the "r" key contains an item in the second Array we based to join. This will be true for every object contained in the output of all the join functions. Notice also that the "id" field in the "l" Object and the "user_id" field in the "r" Object are the same. We defined these fields in the functions we passed to join, and that is how it verified that a relationship existed between these two Array items.
Let's move on to the second object:
{
"l": {
"id": "1",
"name": "Josh"
},
"r": {
"id": "13",
"user_id: "1",
"product: "broccoli"
}
}
The most interesting thing to point out here is that while the name "Josh" appeared in the first Pair, it appeared in the second Pair as well, duplicated. This is because join verified that the user "Josh" has two separate orders.
Finally, looking at the output as a whole, we can see that Daren doesn't appear anywhere. This is because Daren doesn't have any orders (i.e., there are no orders with a "user_id" of "3"), so join ignored him. Also, the book order does not appear in the output either. This is because the there are no associated users with that order (i.e., there are no users with an "id" of “999”).
Use Case - Filtering Unrelated Data
We can use join with reduce to filter out unrelated data from the first and second Array passed to join:
fun filterUnrelatedData(arr1, arr2, idFn1, idFn2) = do {
var relatedData = join(arr1, arr2, idFn1, idFn2)
---
relatedData reduce (pair, out={l: [], r: []}) ->
{
l: if (out.l contains pair.l) out.l else out.l + pair.l,
r: if (out.r contains pair.r) out.r else out.r + pair.r
}
}
Here's the function in action:
filterUnrelatedData(users, orders, (user) -> user.id, (order) -> order.user_id)
// Returns:
// {
// "l": [
// {
// "id": 1,
// "name": "Jerney"
// },
// {
// "id": 2,
// "name": "Marty"
// }
// ],
// "r": [
// {
// "id": 12,
// "user_id": 1,
// "product": "ham"
// },
// {
// "id": 13,
// "user_id": 1,
// "product": "broccoli"
// },
// {
// "id": 15,
// "user_id": 999,
// "product": "book"
// }
// ]
// }
leftJoin
leftJoin works in a very similar way to join, taking the same inputs and producing the same type of output, but leftJoin decides what makes it to the output a little differently than join does. If you remember our Venn diagram from earlier:
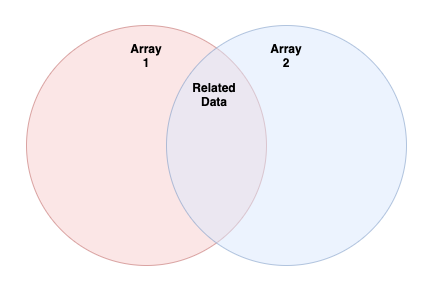
leftJoin will output everything from "Array 1" at least once but will only include data from "Array 2" if there is a match. This means that in the output, which is Array of Pairs, the "l" key in the Pair will always be populated but the "r" key may not be present if a relationship was not found. Let's use our same example from earlier and see how this would look:
leftJoin(users, orders, (user) -> user.id, (order) -> order.user_id)
// Returns:
// [
// {
// "l": {
// "id": "1",
// "name": "Josh"
// },
// "r": {
// "id": "12",
// "user_id: "1",
// "product: "ham"
// }
// },
// {
// "l": {
// "id": "1",
// "name": "Josh"
// },
// "r": {
// "id": "13",
// "user_id: "1",
// "product: "broccoli"
// }
// },
// {
// "l": {
// "id": "2",
// "name": "Marty"
// },
// "r": {
// "id": "14",
// "user_id: "2",
// "product: "guitar strings"
// }
// },
// {
// "l": {
// "id": "3",
// "name": "Daren"
// }
// }
// ]
First, things first: Daren made it! Congrats, buddy! Notice that there is no "r" key in that last Pair, however. This is how leftJoin works: it gives you everything that join would give you, plus anything in the first Array that does not relate to something in the second Array.
Use Case - Getting Unrelated Data from the First Array OR Second Array
A potential use case for leftJoin is determining what items in the first Array do not have a relationship with any items in the second Array. Here's an example:
var leftRelationshipPairs = leftJoin(users, orders, (user) -> user.id, (order) -> order.user_id)
---
relationshipPairs
// Filter pairs that do not have an "r" key
filter ((pair) -> not pair.r?)
// Create an Array mirroring the shape of the original data
map (pair) -> pair.l
// Returns:
// [{"id": 3, "name": "Daren"}]
You can always pull that out into its own function so it has a descriptive name. We can also use reduce instead of the filter/map combination so we can save an iteration through the data incase there's not much to filter. Don't worry about the default key argument right now, its use will become apparent soon:
fun unrelatedLeftData(arr1, arr2, idFn1, idFn2, key="l") = do {
var relatedData = leftJoin(arr1, arr2, idFn1, idFn2)
---
{
"(key)": relatedData reduce (pair, out=[]) ->
if (not pair.r?)
out + pair.l
else
out
}
}
If you need to determine what values in the second Array do not have a relationship with any values in the first Array, you can reverse the inputs to leftJoin. Here's an example with our data:
leftJoin(orders, users, (order) -> order.user_id, (user) -> user.id)
In the output, you would see the order for the book, which has no relationship to any user in the users Array:
[
...,
{
"l": {
"id": "15",
"user_id": "999",
"product": "book"
}
}
]
So if we wanted to write a function unrelatedRightData, that is as simple as wrapping unrelatedLeftData and rearranging the inputs. We also want to pass the key of "r" to unrelatedLeftData so that the output is consistent with the order in which the Arrays are sent into the function:
fun unrelatedRightData(arr1, arr2, idFn1, idFn2) =
unrelatedLeftData(arr2, arr1, idFn2, idFn1, "r")
outerJoin
You can think of outerJoin in terms of leftJoin in that it does the same things as leftJoin does, but it also returns any data from the second Array that doesn't have any matches. This means that all of the data that we pass into the outerJoin will be present in the output in some form. Related data will be grouped, while non-related data will not. If we look at our diagram from earlier:
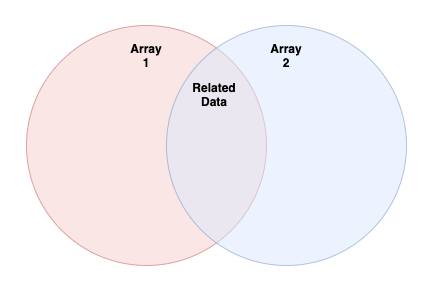
outerJoin will output all of the pairings found in "Related Data", but it will also output all of the items in "Array 1" and "Array 2" that are not related to each other.
Before you read the example coming up, take a moment to hypothesize about what the output will be. What data will be grouped? What data will not be grouped? How will the data that isn't grouped be presented? Will the non-related data in the first Array be displayed differently from the non-related data in the second Array?
Here's the output using our example data:
outerJoin(users, orders, (user) -> user.id, (order) -> order.user_id)
// Returns:
// [
// {
// "l": {
// "id": "1",
// "name": "Jerney"
// },
// "r": {
// "id": "12",
// "user_id": "1",
// "product": "ham"
// }
// },
// {
// "l": {
// "id": "1",
// "name": "Jerney"
// },
// "r": {
// "id": "13",
// "user_id": "1",
// "product": "broccoli"
// }
// },
// {
// "l": {
// "id": "2",
// "name": "Marty"
// },
// "r": {
// "id": "14",
// "user_id": "2",
// "product": "guitar strings"
// }
// },
// {
// "l": {
// "id": "3",
// "name": "Daren"
// }
// },
// {
// "r": {
// "id": "15",
// "user_id": "999",
// "product": "book"
// }
// }
// ]
Notice that this is the same output as leftJoin, except that we now have the following Object from the second Array at the end of the output Array:
{
"r": {
"id": "15",
"user_id": "999",
"product": "book"
}
}
Use Case - Getting Unrelated Data from the First AND Second Array
outerJoin will provide us all the unrelated data from both Arrays, while leftJoin will only provide us unrelated data from the first Array. We can write another function that gets us all the unrelated data in both Arrays:
fun unrelatedData(arr1, arr2, idFn1, idFn2) = do {
var relatedAndUnrelatedData = outerJoin(arr1, arr2, idFn1, idFn2)
---
relatedAndUnrelatedData reduce (pair, out={l: [], r:[]}) ->
{
l: if (pair.l? and not pair.r?) out.l + pair.l else out.l,
r: if (pair.r? and not pair.l?) out.r + pair.r else out.r
}
}
Now we have a suite of four utility functions that we can use to manipulate unrelated data in our input Arrays:
filterUnrelatedData- Get back a Pair with all the unrelated data removed from the input Arrays.unrelatedLeftData- Return only the data in the first Array that is not related to any data in the second ArrayunrelatedRightData- Return only the data in the second Array this is not related to any data in the first ArrayallUnrelatedData- Return the data in the first and second Arrays that is not related to any data in the other Array.
These functions make heavy use of reduce, so if you need a refresher, check out my overview of that function here. The post is suited for DW beginners and more experienced users alike. Here are the functions in one place with documentation if you'd like to drop them into a module:
// Returns a Pair containing the first and second Array with unrelated items removed from each.
// Example:
//
// var arr1 = [{"id": "1", "name": "jerney.io"}, {"id": "2", "name": "Casey"}]
// var arr2 = [{"ext_id": "1", "type": "blog"}, {"ext_id": "3", "type": "commerce"}]
// ---
// filterUnrelatedData(arr1, arr2, (item) -> item.id, (item) -> item.ext_id)
// Returns:
// {
// "l": {
// "id": "1",
// "name": "jerney.io"
// },
// "r": {
// "ext_id": "1",
// "type": "blog"
// }
fun filterUnrelatedData(arr1: Array, arr2: Array, idFn1, idFn2): Pair = do {
var relatedData = join(users, orders, (user) -> user.id, (order) -> order.user_id)
---
relatedData reduce (pair, out={l: [], r: []}) ->
{
l: if (out.l contains pair.l) out.l else out.l + pair.l,
r: if (out.r contains pair.r) out.r else out.r + pair.r
}
}
// Returns a Pair with one key of all the items in the First array that are not related to any items in the second Array
// Example:
//
// var arr1 = [{"id": "1", "name": "jerney.io"}, {"id": "2", "name": "Casey"}]
// var arr2 = [{"ext_id": "1", "type": "blog"}, {"ext_id": "3", "type": "commerce"}]
// ---
// unrelatedLeftData(arr1, arr2, (item) -> item.id, (item) -> item.ext_id)
// Returns:
// {
// "l": [{"id": "2", "name": "Casey"}]
// }
fun unrelatedLeftData(arr1: Array, arr2: Array, idFn1, idFn2, key="l"): Pair = do {
var relatedData = leftJoin(arr1, arr2, idFn1, idFn2)
---
{
"(key)": relatedData reduce (pair, out=[]) ->
if (not pair.r?)
out + pair.l
else
out
}
}
// See: unrelatedLeftData. Gets a list of all the items in the second Array that is not related to the first Array.
fun unrelatedRightData(arr1: Array, arr2: Array, idFn1, idFn2): Pair =
unrelatedLeftData(arr2, arr1, idFn2, idFn1, "r")
// Returns a Pair containing lists of items in the first and second Arrays that are not related to each other.
// Example:
//
// var arr1 = [{"id": "1", "name": "jerney.io"}, {"id": "2", "name": "Casey"}]
// var arr2 = [{"ext_id": "1", "type": "blog"}, {"ext_id": "3", "type": "commerce"}]
// ---
// unrelatedData(arr1, arr2, (item) -> item.id, (item) -> item.ext_id)
// Returns:
// {
// "l": {
// "id": "2",
// "name": "Casey"
// },
// "r": {
// "ext_id": "3",
// "type": "commerce"
// }
fun unrelatedData(arr1: Array, arr2: Array, idFn1, idFn2): Pair = do {
var relatedAndUnrelatedData = outerJoin(arr1, arr2, idFn1, idFn2)
---
relatedAndUnrelatedData reduce (pair, out={l: [], r:[]}) ->
{
l: if (pair.l? and not pair.r?) out.l + pair.l else out.l,
r: if (pair.r? and not pair.l?) out.r + pair.r else out.r
}
}
Conclusion
In this post we've discussed how the join functions in the DataWeave Array module work. We've seen that they all take in the same input: a couple of Arrays and a couple of functions that describe how to extract IDs from items in the Arrays. These functions give us virtually infinite flexibility in defining how to extract IDs. As output, we get an Array of Pairs. We found that the only difference between join, leftJoin, and outerJoin is what they do with Array items in the two Arrays that are unrelated to each other. Here's an overview:
join- Ignore all unrelated data from the first and second ArraysleftJoin- Only ignore unlrelated data from the second ArrayouterJoin- Do not ignore unrelated data in either Array
We also created four functions on top of the joins that allow us to filter or extract unrelated data between two Arrays:
filterUnrelatedData- Remove unrelated data from both input ArraysunrelatedLeftData- Extract unrelated data from the first ArrayunrelatedRightData- Extract unrelated data from the second ArrayunrelatedData- Extract unrelated data from both input Arrays
Thanks for reading! If you enjoyed this post, feel free to follow me on Twitter (@jerney_io) or connect with me on LinkedIn for more content.