Lessons Learned - Using Queues in your Application Architecture
An honest story of my first time using queues to communicate between microservices. Learn from my mistakes so you don't make the same ones!

I recently had the opportunity to work on my first set of microservices which communicated with each other through queues. Services I've built in the past have typically communicated with each other synchronously through HTTP requests and responses, aligning with the API-led methodology, so this was something that was completely new for me. As expected, I had quite a few growing pains in the beginning. The rest of this post will detail those issues so that hopefully you can enter into this scenario knowing what to expect, and avoid some of the issues
This post won't go into detail on motivations, benefits or tradeoffs when it comes to using queues. These topics are outside of the scope of this post.
Tools Used
We decided to use Amazon Web Service's queue offering, SQS, for this solution, and the Anypoint Platform to create integrations and deploy applications. MuleSoft's SQS connector is used to operate the queues.
Diagram
To give us a common base to discuss the topic, we'll assume the following architecture:
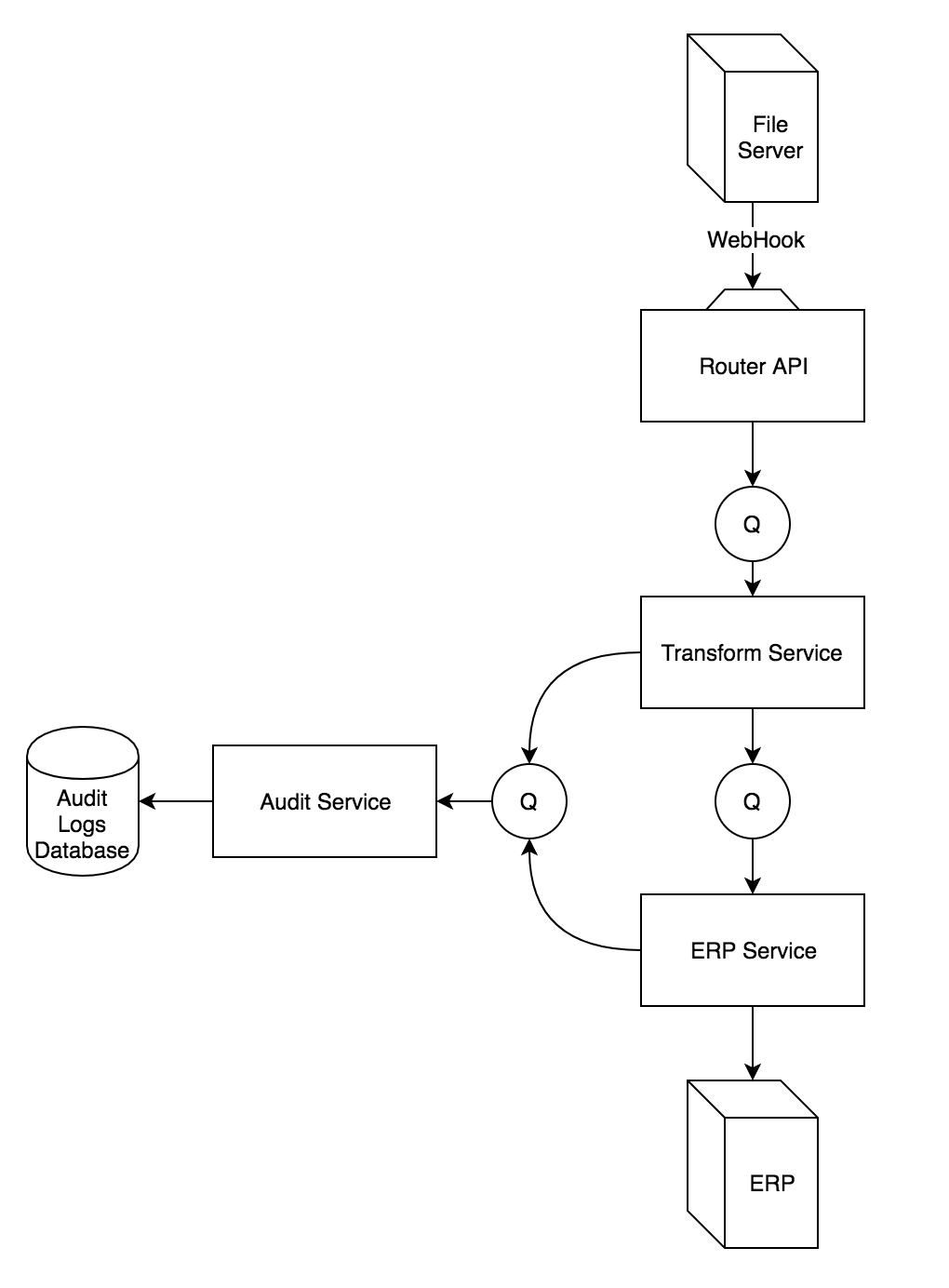
Where the point of origin of a message is a WebHook from the File Server to the Router API. This WebHook is triggered when a file is uploaded to the File Server. The body of the request contains metadata about where the file resides on the server, file size, the email of the user who uploaded the file, etc.
The Router API deals with delivering the inbound message to the appropriate Transform Service based on the file metadata. For the sake of simplicity, we'll just assume one Transform Service.
When the Transform Service receives the data, it pulls the file from the server, transforms the data to prepare it for the ERP service, and pushes the data to the ERP Service queue. It also sends a message to the Audit Service queue for tracking purposes.
The ERP Service pulls the message off the queue and processes it. Its responsibilities include uploading the data to the ERP application and updating the Audit Service via its queue.
Explicitly Managing Message Lifetime
When passing messages between applications with queues, it's important to realize how much more responsibility you have over managing message lifetime than when creating RESTful APIs. You need to decide how often you will check for messages, when you will delete messages, and where messages are sent. Error handling also ends up dumping more complexity into the application code than normal, because you need to decide under which conditions you will try to recover from the error, under which conditions you will push the message to a dead-letter queue, under which conditions you will drop the message completely, etc. These scenarios are subject to complex buisness logic.
Bug 1: Deleting Messages from the Inbound Queue
We'll start with the first problem I encounted: Messages "disappearing" from queues. This happened during development, and was the result of some incorrect assumptions I had about how SQS handled messages after they were read from the queue. I would spin up my API and services, then drop a message on the server. The Transform Service would work fine, but a bug in the ERP Service would cause an exception. No problem. I identified the bug, modified the ERP Service code to fix it, redeployed the app, and waited for it to grab the original message off of the queue. And I waited. And waited. And waited. But the message never came. Turns out there were no messages in the queue at all. This is because by default, the SQS connector deletes the message from the queue on read. In some situations, this might be appropriate, but not for ours. One of the major reasons this architecture was designed this way was to reduce the liklihood of message loss. We wanted to make sure that if the ERP Service went down in the middle of processing a message, that we could stand the service back up and give it another chance at processing that same message. Luckily, this is an easy fix:
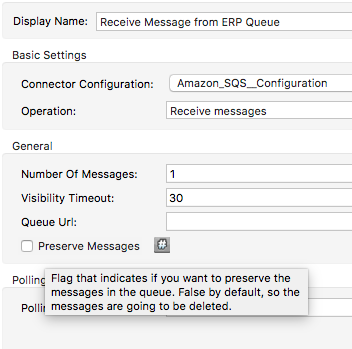
That tooltip is for the "Preserve Messages" checkbox. If you don't want to delete a message from the queue on read, you just check that box. Bug squashed.
Bug 2: Failure To Delete Messages from the Inbound Queue
... Or so I thought. It's sometimes the case that fixing one bug causes another one to pop up, like a game of Whack-a-Mole. After setting the configuration needed to provide more resiliance to the system, my coworker identified another problem. "Josh, there are over 500 messages in the ERP queue, and it keeps growing." At this point we'd dropped maybe 10 - 20 messages onto the file server throughout the day. So at the most we should've have 20 messages on the queue. 500 messages pointed to a serious problem. I asked my collegue how many messages the Transform queue contained, and if it was also growing. She responded it only contained a couple of messages, and that count was stable. So, here's the information I had to work with:
- There was a disproportionate amount of messages in the downstream ERP queue compared with the upstream Transform queue
- The number of messages in the downstream queue was growing
- The number of messages in the upstream queue was not growing
- We had finished testing hours ago and there were still messages in the queues
Oh yeah, and I just set up all the queues to no longer delete messages on read. In fact, messages were never deleted from the queues. What was happening was the Transform Service was continuously pulling the same message from its inbound queue, processing it, and posting it to the ERP queue over and over again. It never went back to delete the message from the inbound queue. From the perspective of the Transform Service, it still had messages to process from the queue, so it kept on processing them.
When working with queues (at least in the case of SQS), you need to be relatively explicit about how messages are handled. It's not like a flow with an HTTP listener where the delievery of the message is handled for you. I had just assumed that the message was going to be deleted from the inbound queue after it successfully made it to the outbound queue. That was an assumption I should've checked beforehand. The service needed to explicitly delete the message from the inbound queue after it knew that the message had been successfully passed on to another party (in this case, another queue). Here's the pattern:
<flow name="transformServiceFlow">
<sqs:receive-messages config-ref="Amazon_SQS__In_Configuration" doc:name="Receive Message from Inbound Queue"/>
<set-variable variableName="msgHandle" value="#[message.inboundProperties['sqs.message.receipt.handle']]" doc:name="Set msgHandle"/>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
{a: 'b'}]]></dw:set-payload>
</dw:transform-message>
<sqs:send-message config-ref="Amazon_SQS__Out_Configuration" doc:name="Send Message to ERP Queue"/>
<sqs:delete-message config-ref="Amazon_SQS__In_Configuration" receiptHandle="#[flowVars.msgHandle]" doc:name="Delete Message from Inbound Queue"/>
</flow>
Design Considerations
In the above diagram, the Audit Service is only accessed through its respective queue, it is never called directly. In turn, the Audit Database is only accessed through the Audit Service, never directly. Due to a miscommunications between teams, this was not the case initially. The Transform Service was coded to call a stored procedure on the Audit Database directly. This in itself wasn't horrible, if it was just inserting data and expecting nothing in response, it's an easy fix. What was horrible was that the client calling the stored procedure was expecting a return value that was going to be used in subsequent calls for tracking purposes (namely, the final call to the Audit Database in the ERP Service). This meant the stord procedure code would need to be modified, and all Transport Services and the ERP Service would need to modified to remove this design flaw.
I can't stress enough how important it is to fully understand that when a message goes into a queue, you will never receive a response, and that's a good thing. It's equally important that your team, or anyone else that has any say in the solution design understands the ramifications of this, as well. If they don't, it is well worth the investment to educate these parties
It might not seem like a huge deal to call the database directly, but the second we wrote code that expected something back from an external application, we took on a dependency that we needed to handle. The Transport and ERP Services now knew too much about the external application, and in their mis-designed state, would crash if the database was down. By putting the database and its respective service behind a queue, and modifying the client services so that they expect nothing in return, these issues are resolved.
We still needed a solution for tracking, however. This problem is well-understood and has been solved many times before. The applications generate UUIDs within the services, and pass them through the message queues like a transaction ID.
Other Issues
Aside from some enlightening bugs, there were a couple other pain points I encountered when working with queues. First, when you have multiple developers working at the same time with the same queues, things get confusing. Second, with all the literature out there from MuleSoft being about API-led integrations and Application Networks, it's hard to find material on building asynchronous-messaging architectures using MuleSoft products. When using a tool like the SQS connector, a lot of times you're on your own when it comes to debugging.
Second, when multiple developers are working at the same time with the same queues, you're going to experience some unpredicable behavior. Imagine a scenario where two developers are both running the Transform Service, and the ERP Service. Developer A's application, pulls the message off the Transport queue, processes it, and pushes the message to the ERP queue. Then Developer B's instance of the ERP Service pulls the message off the ERP and processes it. This is exactly the kind of resiliancy you might be looking for in your production environment, but in your development environment it's downright confusing. From the perspective of Developer A, her message was pushed onto the ERP queue and was subsequently dropped from the queue without notification. From the perspective of Developer B, a rogue message popped on the ERP queue and was processed by his instance of the ERP Service.
As a solution to this scenario, if money permits, you can duplicate the queues for every developer working on the project so that they can test the interactions between applications locally. If you're not using a queue service that is completely hosted, and it's possible to install the queue software on your computer and run queues locally, do that. If those two solutions are not possible, you're left to scheduling and constant communication with your team to determine when you can test your local developments using queues. Not exactly ideal.
Conclusion
Mistakes were made! I think there are two important takeaways here. First, being able to build effective applications that utilize queues means fully understand how much more explicit you need to be about handling message lifetime. There is no automatic response like with the HTTP Listener. When the message gets pulled from the queue, when it is deleted from the queue, what to do with the message when there's an error, etc., are all situations that you need to explicity account for with code. Second, make sure you take the time to educate the people you're working with on the ramifications of asynchronous message passing. If you're working with a team that has worked with this kind of architecture in the past, you might not need to do anything at all in terms of education (if you're lucky, they'll be the ones educating you!). But if you're working with junior devs, spending a little time up front making sure they understand how the architecture should work and why is going to save you time and money in the long run.