Mule 4: The Strategy Pattern
How to implement the Strategy pattern in Mule 4.

The Strategy pattern is a design pattern in object-oriented (OO) programming. The Strategy pattern is useful if you have an algorithm in mind that can be broken up into two pieces: a base algorithm that never changes, and interchangeable pieces of functionality that can be fed to the base algorithm to perform a task. This pattern is part of the design patterns discussed in the popular book "Design Patterns: Elements of Reusable Object-Oriented Software", by GoF so I'd like to stay consistent with the vocabulary they've put forward. The aformentioned "base algorithm" is refered to as the Context. The Context is what you're actually trying to accomplish, for example, validating a CSV or modifying all items in an array the same way. The "iterchangeable pieces of functionality" are referred to a Concrete Strategies. Concrete Strategies provide the the details of how the Context is accomplished. These Concrete Strategies adhere to a Strategy, which is typically an interface that must be implemented.
Here's a brief overview of the vocabulary associated with the Strategy pattern before we continue:
- Context - what the algorithm is trying to accomplish
- Concrete Strategy - how the algorithm will accomplish the task
- Strategy - an interface that describes the rules of how the Concrete Strategies must be implemented
The Strategy Pattern in DataWeave
If you're not familar with the Strategy pattern already, don't worry, I'd wager that you've already used something incredibly similiar in your DataWeave code. While the Strategy pattern is an OO design pattern, it seems to pull from a very popular pattern used in functoinal programing (FP): passing functions to other functions. You don't have to squint your eyes too hard to see that the Strategy pattern is just emulating what FP languages get at a much lower cost. If you've ever used map, filter, or many other HOFs, you've likely taken advantage of this kind of design. If you've ever developed your own functions that take other functions as a parameter, you've built functionality using this design pattern before.
As a concrete example, consider the map function. The Context is transforming all items in an Array the same way. This is what map aims to accomplish. The Concrete Strategy is whatever function you pass to map. This is what describes how each item in the Array will be transformed. For simplicity's sake, we can say the Strategy is just any function that takes in Any and returns Any. That is how the Concrete Strategy must be formatted.
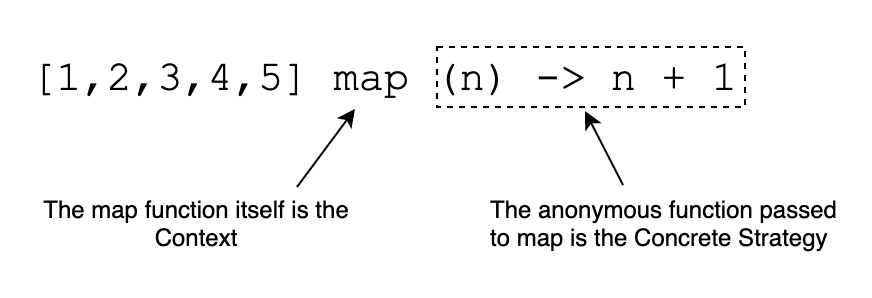
If you understand how the Strategy pattern works in functional programming with the HOF itself as the Context and the functions passed to the HOF as Concrete Strategies, all that's left for us to do is make it more complicated with objects. Once we get to that point, we can discuss how to implement this technique in Mule projects.
The Strategy Pattern in Java
To implement the Strategy pattern in Java, you need three pieces:
- A concrete class to represent the Context
- An interface to represent the Strategy. The Strategy should define the method signature that the Context should expect.
- As many Concrete Strategies as needed. These are classes implementing the interface defined in the previous step.
The job of the Context is to take in a Concrete Strategy, provide context in which the Concrete Strategy can execute, and call the Concrete Strategy. The key here is that the Context doesn't care how the Concrete Strategy is implemented, it only cares that it adheres to the expected Strategy interface. Here's a short example:
// The Strategy
public interface TransformStrategy {
public String transform(String);
}
// The Concrete Strategy
public class Exciter implements TransformStrategy {
public String transform(String str) {
return str + "!!"
}
}
// The Context
public class StringTransformer {
private String str;
private TransformStrategy transformer;
// Takes in a Concrete Strategy
public Context(String str, TransformStrategy transformer) {
this.str = str;
this.transformer = transformer;
}
// Context in which the Concrete Strategy can execute
public String execute() {
// Calls the Concrete Strategy
return this.transformer.transform(str);
}
}
And here's how we'd use them together:
String greeting = "Hello";
TransformerStrategy exciter = new Exciter();
StringTransformer transformer = new StringTransformer(greeting, exciter);
String transformedString = transformer.execute();
System.out.print(transformedString);
// Prints: "Hello!!"
If we wanted to do different string transformations, we could just add new Concrete Strategies that implement the TransformStrategy interface:
// A New Concrete Strategy
public Doubter implements TransformStragegy {
public String transform(String str) {
return str + "?";
}
}
Then we could use it the same way as we did the other Concrete Strategy:
String statement = "You're sure";
TransformerStrategy doubter = new Doubter();
StringTransformer transformer = new StringTransformer(statement, doubter);
String transformedString = transformer.execute();
System.out.print(transformedString);
// Prints: "You're sure?"
I used transforming Strings to illustrate the pattern using something familiar. Indeed, it is overkill to use this pattern for something as straightforward as transforming Strings. How about validating some CSVs?
Validating Different CSV Formats with the Strategy Pattern
Validating CSVs can be accomplished by a libary in most cases, but what if the use case requires that your validations are conditional? For example, if one field has a certain value, another field must have a certain value as well. In my research, the library options dwindle quickly once you get away from validating simple things like the header, the data types of each column, and the length of each row. This leaves us to roll our own solution.
Our validation strategy should adhere to the following:
- It must take in CSVs in the form of
List<Map<Integer, String>> - It should not validate headers
- It must be able to validate fields depending on the values of other fields
- It must allow a client to write additional validation rules without needing to change any existing code.
- Validation rules are only applied to a single row at a time (i.e. we will not be validating data across multiple rows at once)
- The client should receive a boolean true if the validation passed, and false otherwise.
3 is where things get complicated for out-of-the-box CSV validators, and 4 is what really pushes us to use the Strategy pattern to build an extendable solution. 5 and 6 just vastly narrow the scope of what I need to implement for this demo.
If we try to fit this problem into the Strategy pattern, some clear boundaries become apparent. For starters, we know that because of constraints 4 and 5, the validation rules will be our Concrete Strategies, and that each Concrete Strategy will define how to validate a single row of a CSV. Since our Concrete Strategy's job is to validate a single row of a CSV, and not the entire CSV, we know that the Context will need to contain the logic for looping through the CSV. Because of this, we also know we can give the method in our Strategy a name like "validateRow". Let's create a skeleton for how this might work:
public interface CSVRowValidationRule {
public boolean validateRow(Map<Integer, String> row);
}
public class CSVValidator {
private CSVRowValidationRule rule;
public CSVValidator(CSVRowValidationRule rule) {
this.rule = rule;
}
public boolean validate(List<Map<Integer, String>> csv) {
for (Map<Integer, String> row : csv) {
if (! rule.validateRow(row)) {
return false;
}
}
return true;
}
}
Please note that I'm representing a CSV row as Map<Integer, String>. The Integer represents the column number where the String value is present.
Now let's assume we have a CSV like the following (spaces added for clarity):
12, 12/12/2011, 01/01/2012, 512.13
13, 06/14/2011, 01/01/2015, 12.67
14, 07/01/2011, 01/01/2012, 2.65
15, 02/17/2011, 01/01/2015, 90.22
The first column is an ID, which we want to verify is present. The second and third columns are dates. The first is a start date, and the second is an end date. We want to verify that the dates ahere to a particular format, and then make sure that the end date takes place after the start date. Finally, the last column is an amount. We want to make sure that is positive. Here's how we might implement those validations requirements as a Concrete Strategy for our CSVValidator:
public class CSVType1Validator implements CSVRowValidationRule {
private SimpleDateFormat df = new SimpleDateFormat("MM/dd/yyyy");
@Override
public boolean validateRow(Map<Integer, String> row) {
String id = row.get(0);
String startDateStr = row.get(1);
String endDateStr = row.get(2);
String amount = row.get(3);
if (id == null || id.trim() == "") { return false; }
try {
df.setLenient(false);
Date startDate = df.parse(startDateStr);
Date endDate = df.parse(endDateStr);
if (endDate.before(startDate)) { return false; }
} catch (ParseException e) {
return false;
}
if (Double.parseDouble(amount) < 0) { return false; }
return true;
}
}
Before we put this into a Mule 4 project, let's make sure it works in Java.
public class Main {
public static void main(String[] args) {
// Creates same CSV we referenced earlier
List<Map<Integer, String>> csv = createCsv();
// Validate CSV
CSVRowValidationRule validationRule = new CSVType1Validator();
CSVValidator validator = new CSVValidator(validationRule);
boolean pass = validator.validate(csv);
if (pass) {
System.out.println("CSV Passed Validation");
} else {
System.out.println("CSV Failed Validation");
}
}
private static List<Map<Integer, String>> createCsv() {
...
}
}
This should print out "CSV Passed Validation". You can modify the data in the "createCsv" method and check out if the validation fails when expected.
We can add an additional Concrete Strategy and use that when needed. We'll create a simple rule that verifies that each row has 5 records:
public class CSVDefaultValidator implements CSVRowValidationRule {
@Override
public boolean validateRow(List<String> row) {
return row.size() == 5;
}
}
To test it out, just swap the following line in main:
// Validate CSV
CSVRowValidationRule validationRule = new CSVType1Validator();
With this:
// Validate CSV
CSVRowValidationRule validationRule = new CSVDefaultValidator();
Implementing the Strategy Pattern in Mule 4
Once you have your Strategy working in Java, it's time to embed it in your Mule 4 application. Thanks to the Java Module, and some of the work that AP Studio does for us, this ends up being one of the least painful parts of the process. In general, you will need to use the Java Module three separate times:
- New - Instantiate the Concrete Strategy
- New - Instantiate the Context with the Concreate Strategy
- Invoke - Call the relevant method on the Context with your data
Here's a graphical example:
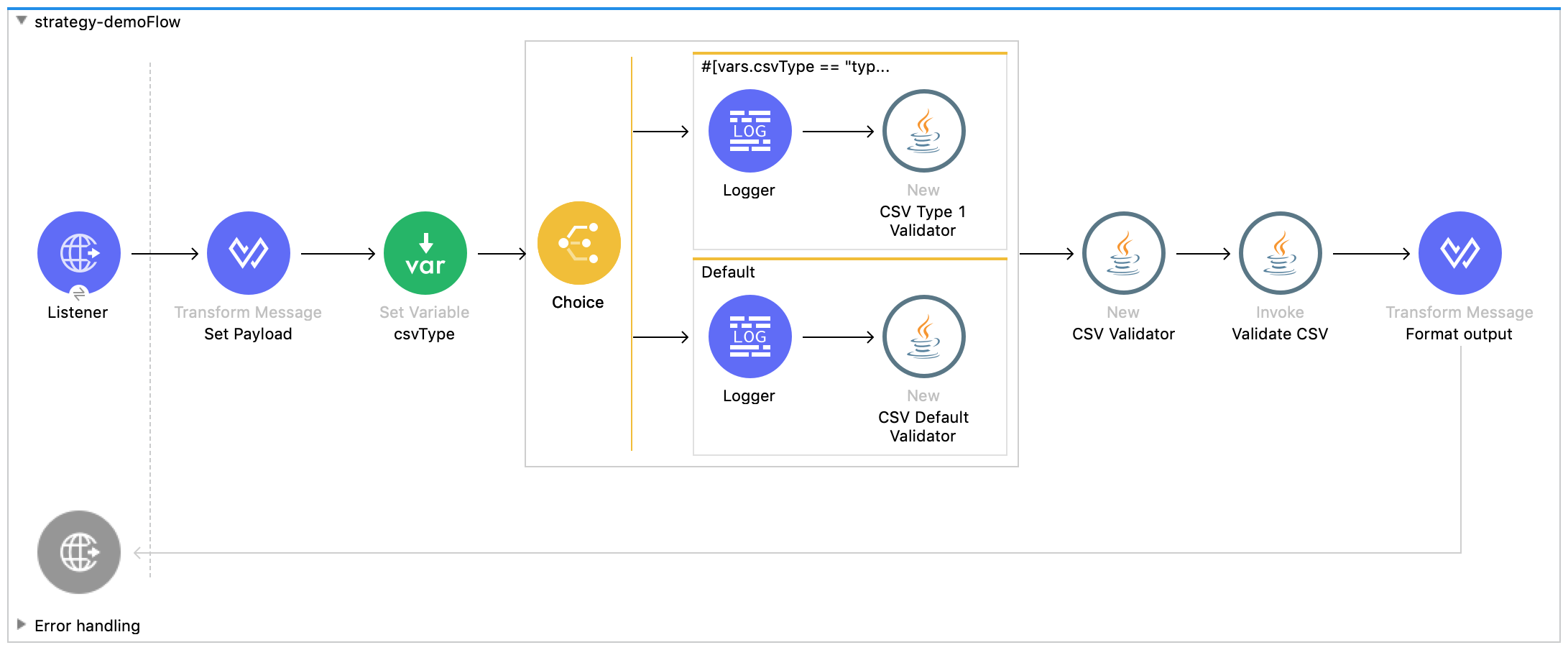
While the choice router is unecessary to demonstrate the Strategy pattern, it illustrates that you can use multiple different Concrete Strategies depending on a criteria that you define. In this case, I'm setting a variable in the previous component, and checking that variable in the choice router to determine what Concrete Strategy should be used to validate the data. To create the Context, we need to use "New" from the Java module again. This time, we need to pass in our existing rule which was set to vars.validationRule. Here's how that looks:
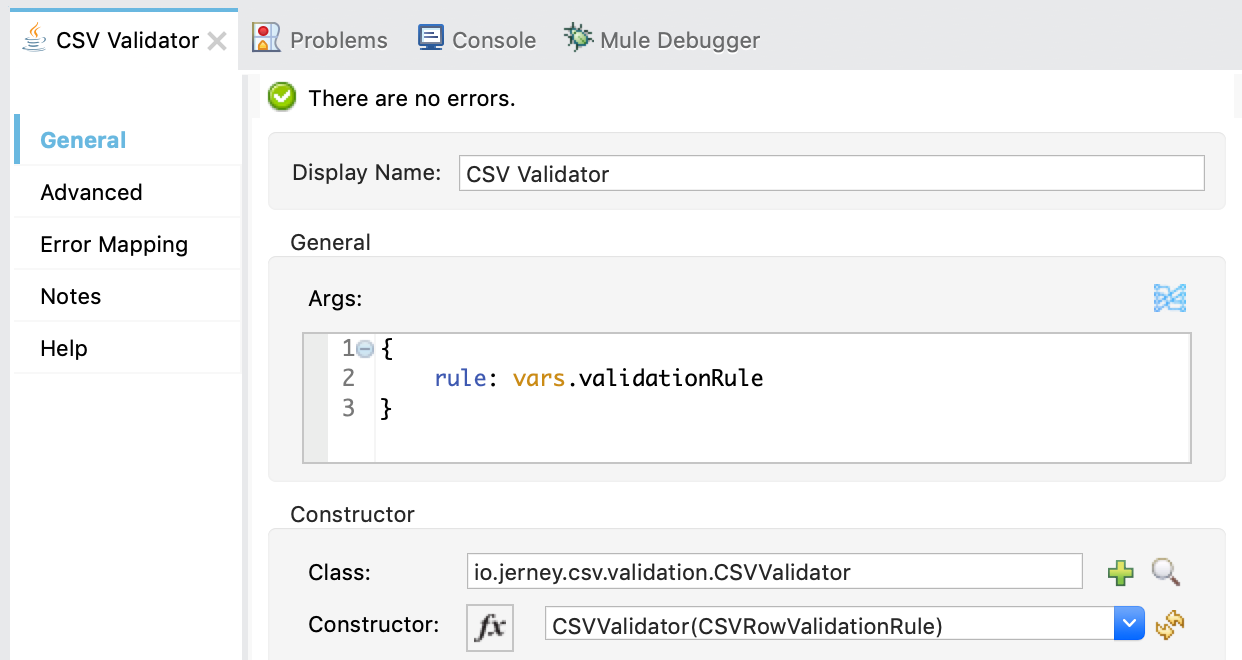
The result of this operation is set to vars.csvValidator. Finally, we need to invoke the validate method on the Context. That's done in the next step with "Invoke" from the Java module:
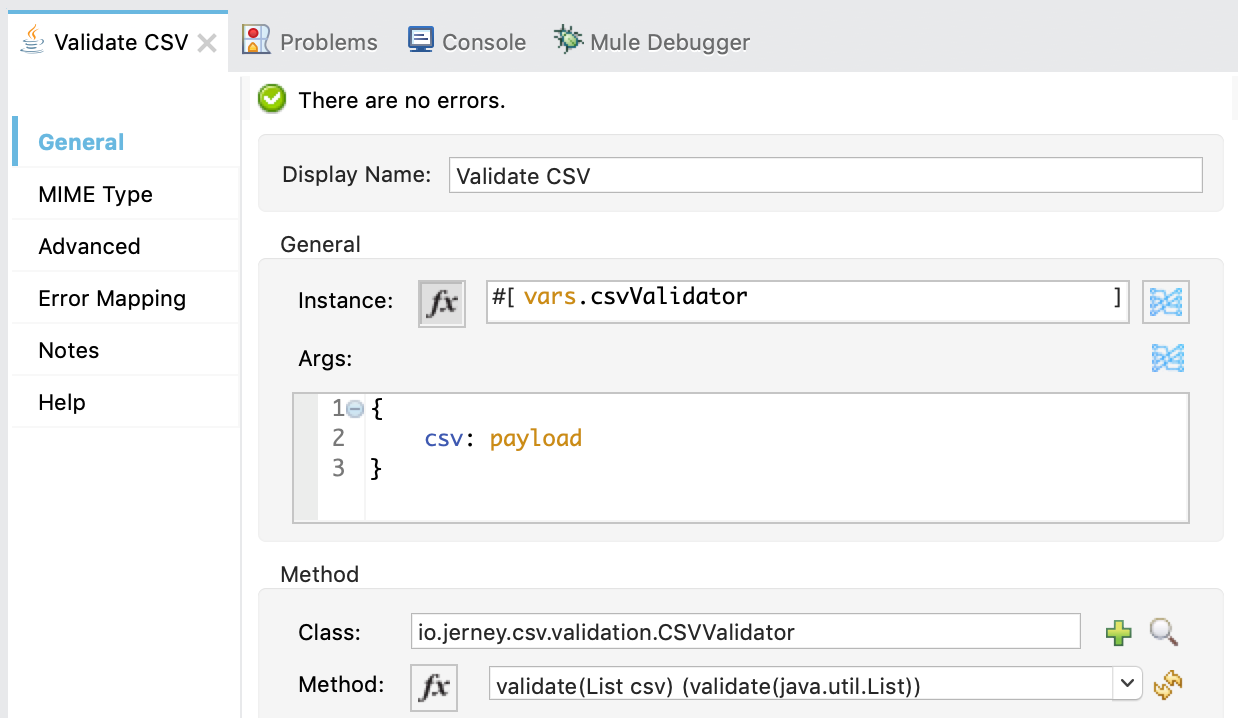
What's nice about this whole process is that you don't have to look at any Java code if you don't need to. We have our Mule world cleanly separated from our Java world.
If you'd like to take a deeper dive into the code or view the XML, I've added the example Mule project to my GitHub here. Thanks for reading!